Shuffling and Splitting Pandas DataFrame
For uniform data distribution among training, validation and test data

For uniform data distribution among training, validation and test data
Packages Needed: numpy, pandas
While training a Machine Learning model, the training dataset is usually split into the following subsets:
- Training data (60 % of input data)
- Validation data (20 % of input data)
- Test data (20 % of input data)
When splitting a dataset in its origin form, the dataset with similar features might be put in the same subset. For example, let us consider this car dataset. After importing into our code as aPandas DataFrame, we have the following output when we print head() of the dataset.
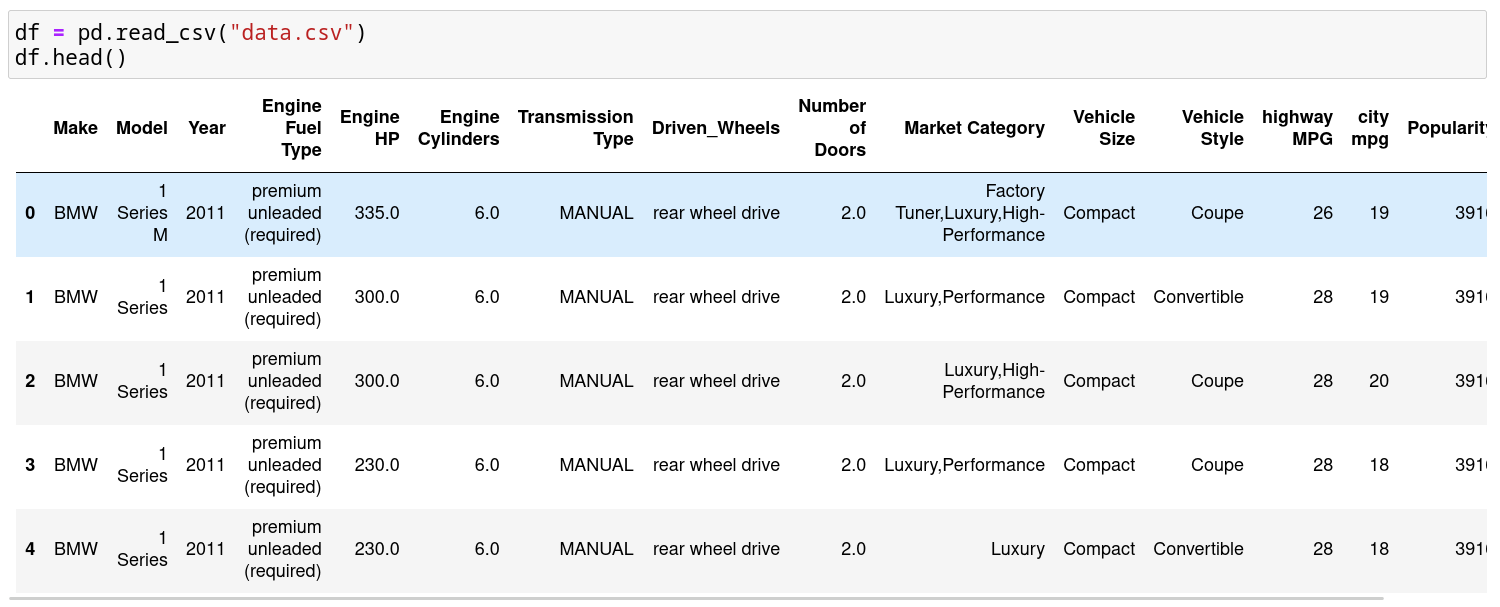
If the dataset is split in its current form, data about BMW cars will be present in the first 60% of the input data (training data) only and data with similar features will be in the same data subsets.
So, dataset need to be shuffled before it is split into subsets. This is done as follows:
1. Create an array of the same length as the dataset
n = len(df)
idx = np.arange(n)
The idx array will be used as the index array for new DataFrames.
2. Shuffle the index array
np.random.seed(2)
np.random.shuffle(idx)
Here, the seed is set so that the shuffled indexes are always the same. This is to provide consistence in datasets in future training sessions.
NOTE: The seed can be set to any number.
3. Slice the DataFrame
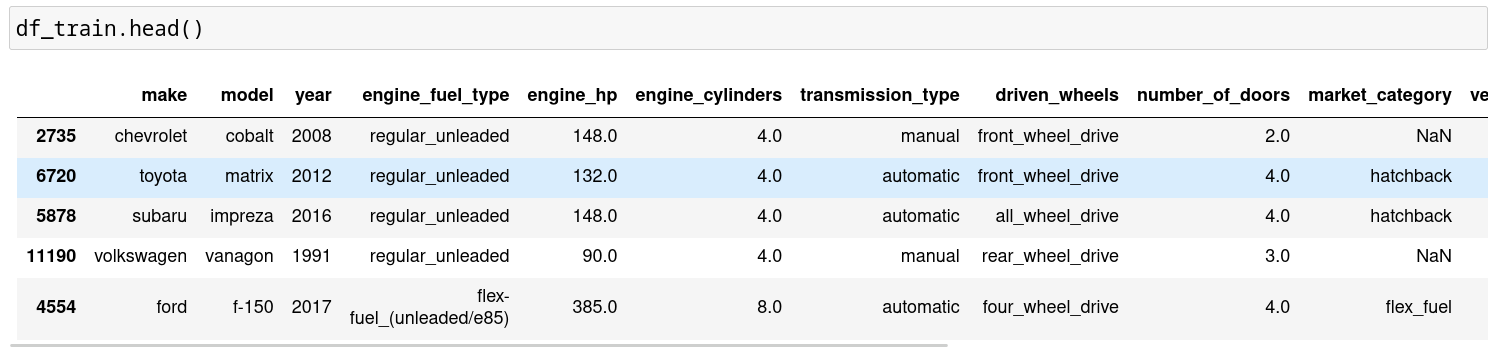
The DataFrame is split into train, validation and test DataFrames where data with similar features are uniformly distributed.
df_train = df.iloc[idx[:n_train]]
df_val = df.iloc[idx[n_train:n_train+n_val]]
df_test = df.iloc[idx[n_train+n_val:]]
4. Reset the indices
The indices on the training, validation and test DataFrames are not in order, and we will reset the indices.
df_train = df_train.reset_index(drop=True)
df_val = df_val.reset_index(drop=True)
df_test = df_test.reset_index(drop=True)
So, that's how we shuffle the DataFrame to have similar features distributed across its subsets.